Stai modificando un video con più relatori, magari un podcast o un'intervista. Aggiungere manualmente i sottotitoli è noioso:devi ascoltare, digitare e sincronizzare ogni parola pronunciata. E se il tuo editor video potesse riconoscere automaticamente voci diverse e generare sottotitoli per ciascun oratore? È qui che entra in gioco il riconoscimento del parlante in Python cambia il gioco.
Python è il linguaggio di programmazione di prima scelta per lo sviluppo di applicazioni basate sulla voce grazie alle sue robuste librerie. Queste librerie ti aiutano a implementare e distribuire modelli di riconoscimento degli oratori per l'elaborazione, l'analisi e l'identificazione degli oratori in tempo reale. Ad esempio, Pico Voice Eagle SDK offre un'identificazione rapida e precisa dell'oratore per applicazioni basate sull'intelligenza artificiale.
In alternativa esistono piattaforme di editing video che integrano l’intelligenza artificiale per il riconoscimento vocale. Funzionano scansionando l'audio del video, distinguendo gli interlocutori e generando sottotitoli sincronizzati.
Questa guida esplorerà come implementare l'identificazione del parlante in Python. Esamineremo anche le migliori alternative senza codice per sottotitoli video senza sforzo.

In questo articolo
- Fondamenti di elaborazione audio
- Identificazione del relatore in tempo reale con Picovoice Eagle SDK
- Esistono modi più semplici per eseguire il riconoscimento del relatore?
- Dove posso utilizzare le app di riconoscimento del relatore?
Parte 1:Fondamenti di elaborazione audio

Ogni sistema di riconoscimento vocale inizia con l'elaborazione audio. Il suono viaggia come segnali analogici continui, ma i computer richiedono formati digitali. Per convertire il parlato in dati, utilizziamo frequenze di campionamento e tecniche di codifica audio.
Una frequenza di campionamento definisce la frequenza con cui il suono viene registrato al secondo. Lo standard per il riconoscimento degli altoparlanti Python è 16 kHz, garantendo un'elevata precisione. Anche il formato del file audio è importante:WAV, MP3 e FLAC sono opzioni comuni, con WAV preferito per le attività di machine learning.
Python semplifica l'identificazione degli oratori in tempo reale con librerie specializzate come PyAudio e Picovoice Eagle SDK. Utilizzando questi strumenti, gli sviluppatori possono acquisire, analizzare e addestrare modelli per l'identificazione degli oratori in tempo reale in Python.
Parte 2:identificazione dell'oratore in tempo reale con Picovoice Eagle SDK
Picovoice Eagle SDK è uno strumento ad alte prestazioni per il riconoscimento degli oratori in Python . A differenza dei modelli tradizionali, elabora l'audio localmente. Questo SDK è fondamentale per l'identificazione degli oratori in tempo reale in Python, in particolare nei sistemi di sicurezza AI e negli assistenti intelligenti.
Inoltre, è leggero e funziona perfettamente su più piattaforme, tra cui Windows, macOS, Linux, Android, iOS e persino Raspberry Pi. Devi solo registrarti alla console Pico Voice e ottenere la chiave di accesso per autenticare il tuo utilizzo.
Installazione e configurazione dell'SDK Pico Voice Eagle in Python
Per integrare Picovoice Eagle SDK per il riconoscimento degli oratori in Python, installalo prima. Prima di farlo, assicurati di avere installato Python 3.6+.
Apri un terminale (Linux/macOS) o un prompt dei comandi (Windows) ed esegui:
o
Se Python è installato, verrà visualizzato qualcosa del tipo:
Se la versione è 3.6 o successiva, sei a posto.
Per iniziare, installa le librerie necessarie. Esegui quanto segue nel tuo terminale:
pip install SpeechRecognition pyaudio librosa pvrecorder
Per Picovoice Eagle SDK, scarica e installa:
pip installa pvporcupine pveagle
Guida passo passo per implementare l'identificazione degli oratori in tempo reale utilizzando Picovoice Eagle SDK in Python
- Passaggio 1:installa Python. Sul sito web ufficiale di Python, seleziona l'opzione per scaricare la versione più recente, Python 3. x.x.
- Passaggio 2: successivamente, registrati per un account gratuito della console Picovoice e recupera la chiave di accesso. Questa chiave è necessaria per autenticare le tue richieste quando utilizzi Eagle Speaker Recognition SDK.
- Passaggio 3: installa i pacchetti Python necessari. Esegui il seguente comando nel tuo terminale:
pip installa pveagle pvrecorder
Verranno installati PV Eagle (per il riconoscimento dell'oratore) e PV Recorder (per l'acquisizione audio).
- Passaggio 4: crea due file nel tuo VsCode. Il primo file sarà quello di iscrivere un relatore. La registrazione è il processo di creazione di un profilo del relatore basato sui dati vocali. Segui questi passaggi:
- Importa le librerie richieste
- Inizializza EagleProfile con la tua chiave di accesso
- Utilizza il registratore PV per acquisire campioni vocali
- Inserisci frame audio in EagleProfile fino al completamento della registrazione
- Esporta il profilo del relatore per un riconoscimento futuro
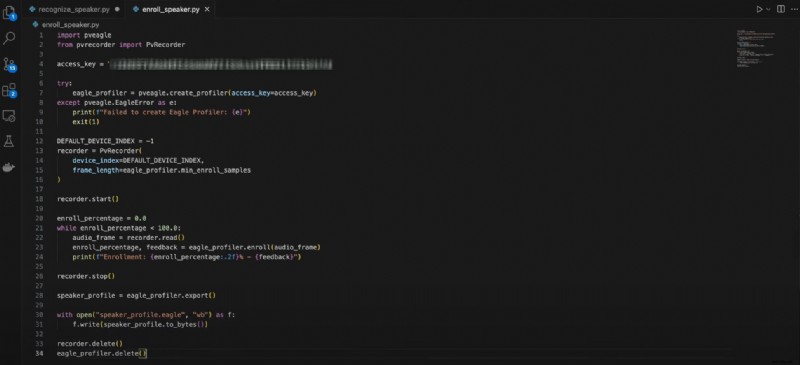
Ecco il codice per la registrazione del relatore:
importa pveagleda pvrecorder importa PvRecorder
access_key ="LA TUA_CHIAVE_ACCESSO"
prova:
eagle_profiler =pveagle.create_profiler(access_key=access_key)
tranne pveagle.EagleError come e:
print(f"Impossibile creare Eagle Profiler:{e}")
esci(1)
DEFAULT_DEVICE_INDEX =-1
registratore =Registratore Pv(
indice_dispositivo=DEFAULT_DEVICE_INDEX,
frame_length=eagle_profiler.min_enroll_samples
)
registratore.start()
percentuale_iscrizione =0,0
mentre percentuale_iscrizione <100,0:
audio_frame =registratore.read()
enroll_percentage, feedback =eagle_profiler.enroll(audio_frame)
print(f"Iscrizione:{enroll_percentage:.2f}% - {feedback}")
registratore.stop()
profilo_altoparlante =eagle_profiler.export()
con open("speaker_profile.eagle", "wb") come f:
f.write(speaker_profile.to_bytes())
registratore.delete()
eagle_profiler.delete()
- Passaggio 5:vai al tuo terminale e registra inserendo il codice seguente
python3 enroll_speaker.py
Una volta eseguito lo script, prova a parlare al microfono. Se la tua voce corrisponde al profilo dell'oratore registrato, verrà stampato "Speaker riconosciuto!" Altrimenti indicherà un parlante sconosciuto.

- Passaggio 6: ora che il profilo del relatore è pronto, creiamo un codice per il riconoscimento del relatore in tempo reale sul secondo file. Questo carica un profilo dell'oratore e riconosce un oratore in tempo reale utilizzando Pico Voice Eagle SDK.
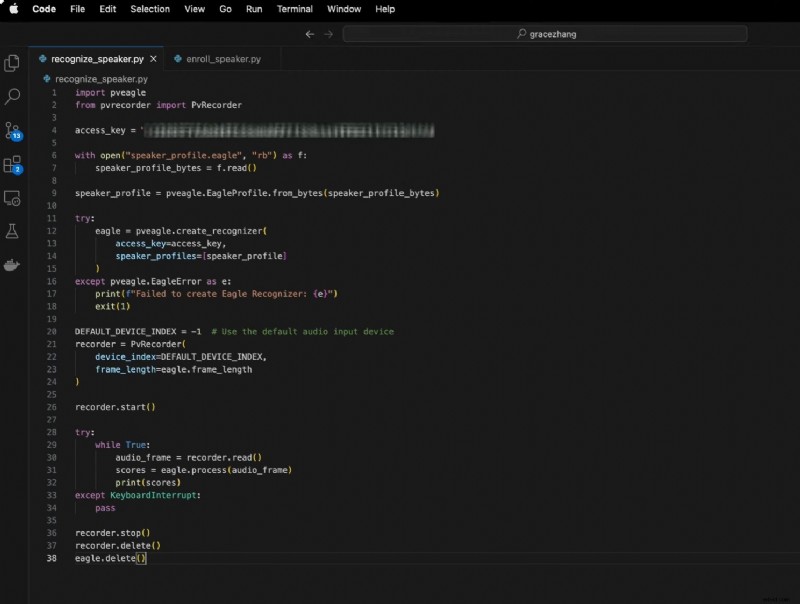
Ciò comporta:
- Creazione di un'istanza Eagle con la chiave di accesso e il profilo dell'altoparlante
- Utilizzo del registratore PV per acquisire audio dal vivo
- Passare i frame audio a Eagle per il riconoscimento in tempo reale
Ecco il codice:
importare pveagleda pvrecorder importa PvRecorder
access_key ="LA TUA_CHIAVE_ACCESSO"
con open("speaker_profile.eagle", "rb") come f:
speaker_profile_bytes =f.read()
profilo_altoparlante =pveagle.EagleProfile.from_bytes(profilo_altoparlante_bytes)
prova:
aquila =pveagle.create_recognizer(
chiave_accesso=chiave_accesso,
speaker_profiles=[profilo_altoparlante]
)
tranne pveagle.EagleError come e:
print(f"Impossibile creare Eagle Recognizer:{e}")
esci(1)
DEFAULT_DEVICE_INDEX =-1 # Utilizza il dispositivo di input audio predefinito
registratore =Registratore Pv(
indice_dispositivo=DEFAULT_DEVICE_INDEX,
lunghezza_frame=aquila.lunghezza_frame
)
registratore.start()
prova:
mentre Vero:
audio_frame =registratore.read()
punteggi =eagle.process(audio_frame)
stampa(punteggi)
tranne KeyboardInterrupt:
passare
registratore.stop()
registratore.delete()
aquila.delete()
- Passaggio 7:testare ed eseguire l'applicazione.
Python3 recognize_speaker.py
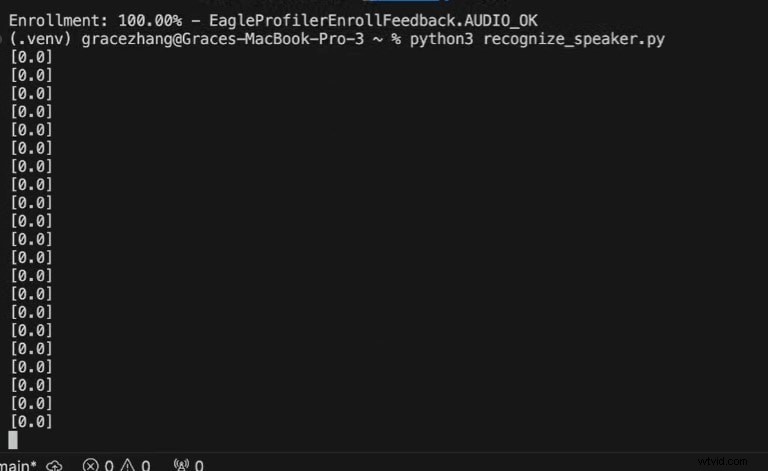
0 =Voce non riconosciuta
1 =Voce riconosciuta

Nota:a differenza dei modelli basati su cloud, Picovoice Eagle SDK elabora i dati localmente. Ciò garantisce risultati più rapidi, migliore privacy e nessuna dipendenza da Internet.
L'identificazione del relatore in Python può essere compresa ed eseguita solo da programmatori professionisti. È necessario avere una certa conoscenza della programmazione per comprendere il processo.
Parte 3:esistono modi più semplici per eseguire il riconoscimento del relatore?
La creazione di un sistema di riconoscimento degli altoparlanti Python richiede competenze di codifica e conoscenze tecniche. Sebbene l'identificazione in Python sia potente, può essere difficile per i non programmatori. Molti utenti preferiscono strumenti già pronti che offrono funzionalità simili di altoparlante e riconoscimento vocale. È un modo migliore per portare a termine l'attività senza competenze di programmazione.
Uno di questi strumenti è WondershareFilmora, un editor video con riconoscimento dell'oratore integrato e modifica del parlato. Consente agli utenti di rilevare, trascrivere e modificare le registrazioni vocali senza scrivere una sola riga di codice.
A differenza del riconoscimento degli altoparlanti Python, che richiede l'addestramento manuale del modello, gli strumenti integrati di Filmora automatizzano il processo. Puoi modificare e migliorare i file audio senza bisogno di conoscenze di Python o di machine learning. Ciò rende l'identificazione del relatore accessibile a creatori di contenuti, operatori di marketing e utenti aziendali.
Funzioni di rilevamento degli altoparlanti mobili e modifica vocale di Filmora
Filmora integra uno strumento basato sull'intelligenza artificiale che semplifica l'editing audio e il riconoscimento degli oratori. Con la sua versione mobile, gli utenti possono accedere alle funzionalità di rilevamento dell'oratore e di modifica del parlato.
- Rilevamento degli altoparlanti.Il rilevamento degli altoparlanti analizza l'audio e distingue tra diversi altoparlanti. Invece del modo manuale di ascoltare e taggare le voci, l'intelligenza artificiale identifica chi sta parlando e quando.
- Modifica del discorso. La modifica del parlato può essere noiosa, ma la modifica del parlato di Filmora semplifica il processo. Consente agli utenti di modificare le registrazioni vocali, regolare la chiarezza e rimuovere il rumore di fondo.
Come riconoscere la voce, convertire in testo e modificare utilizzando Filmora in movimento
Filmora semplifica il riconoscimento degli oratori con pochi clic. Ecco una guida passo passo:
- Passaggio 1:scarica Filmora, fai clic su "nuovo progetto e importa il video con la voce.
- Passaggio 2:seleziona il testo per convertire le parole pronunciate in testo.

- Passaggio 3:fai clic sui sottotitoli AI per avviare il processo di riconoscimento vocale
- Passaggio 4: fai clic sull'opzione Rilevamento altoparlante prima di selezionare Aggiungi didascalie
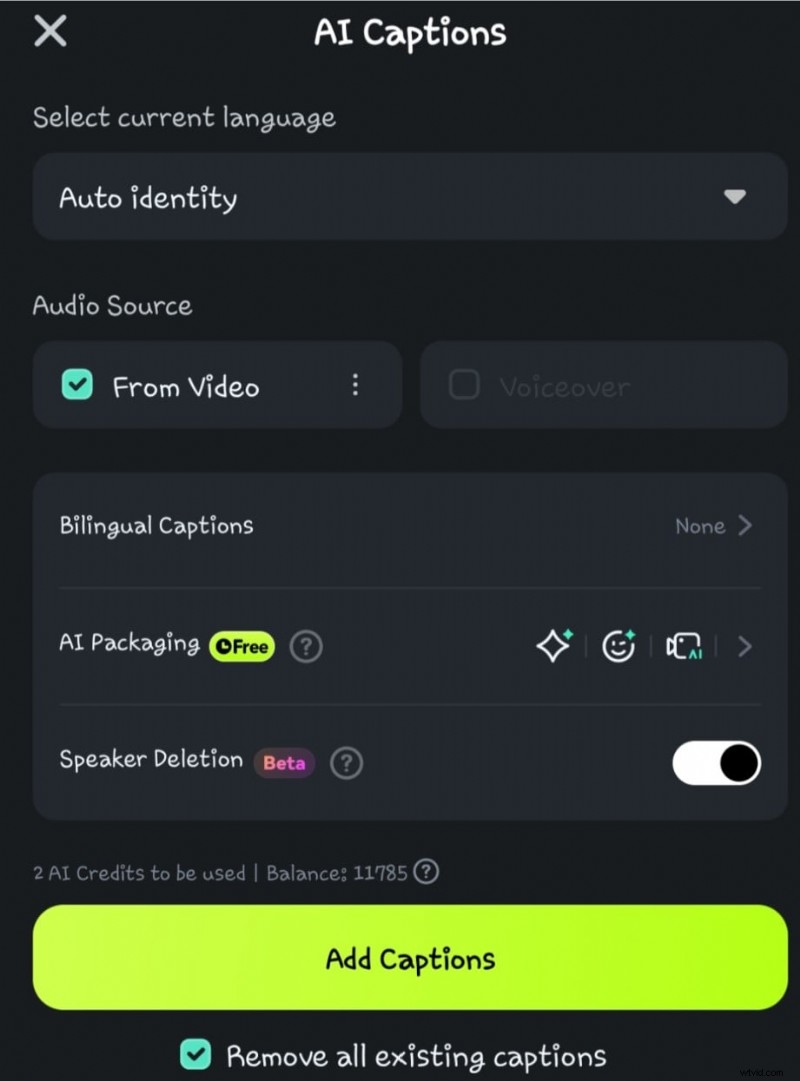
- Passaggio 5: attendi che l'intelligenza artificiale elabori la conversione della voce in testo
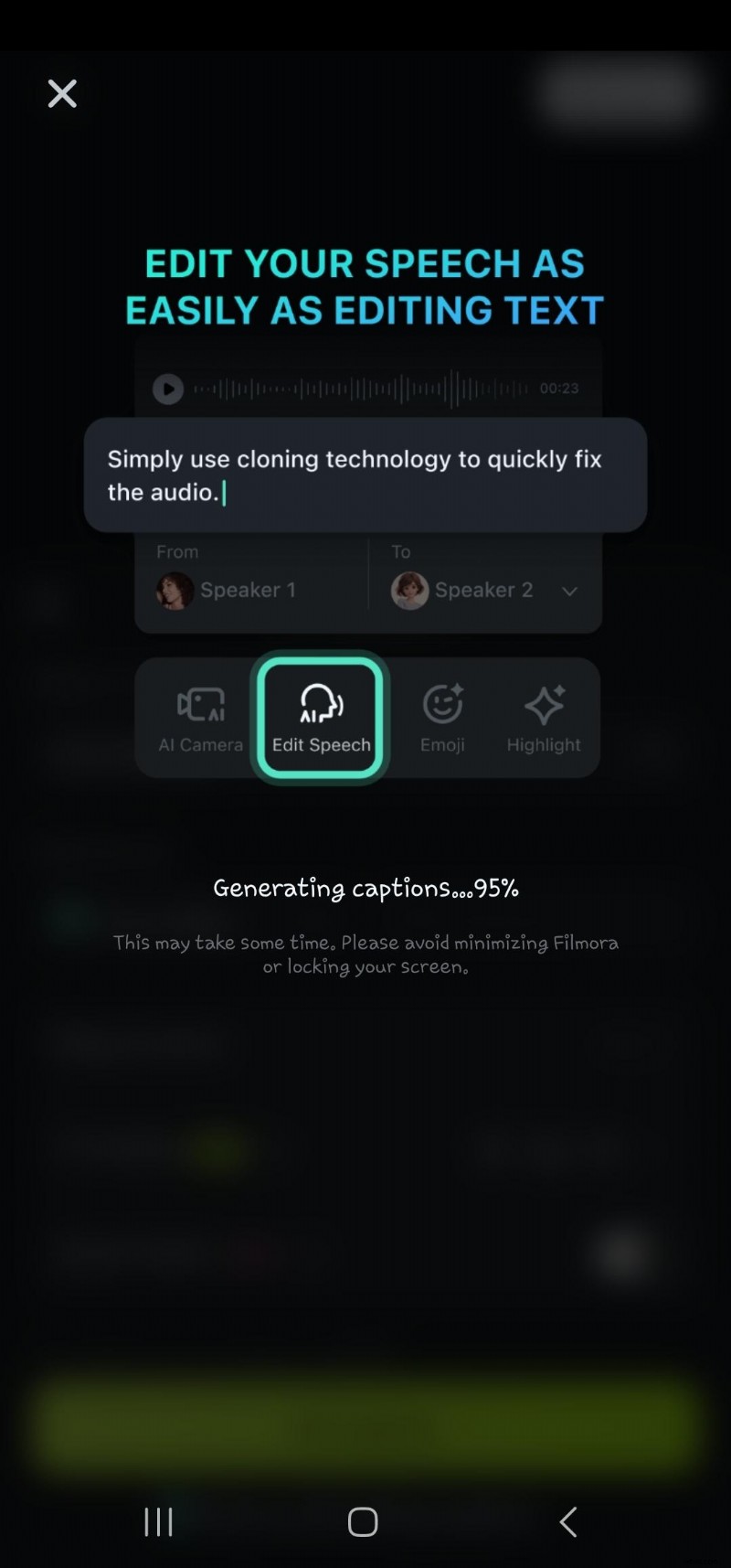
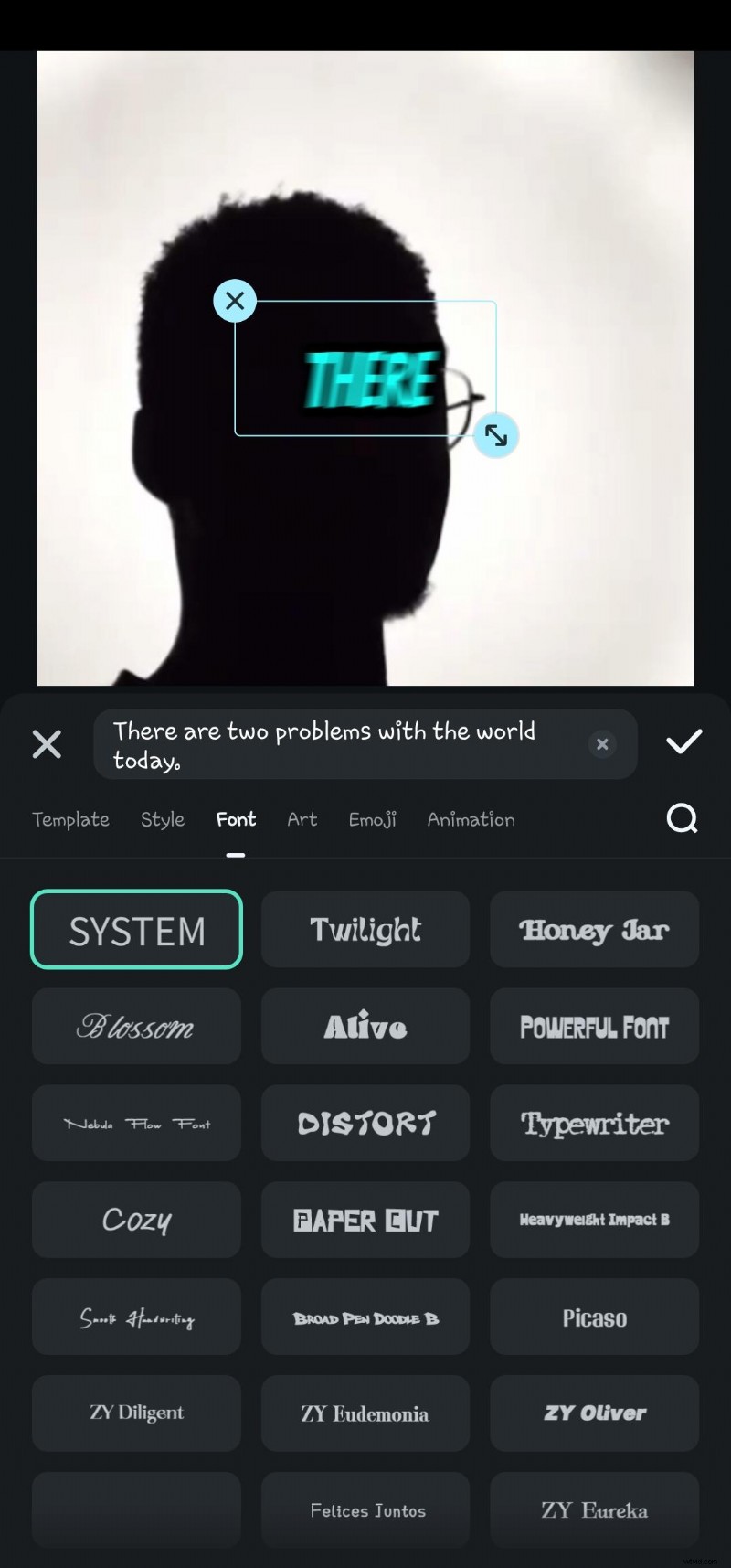
- Passaggio 6:fai doppio clic sul testo generato nella timeline per accedere all'opzione di modifica del parlato. Qui puoi aggiungere animazioni, modificare il modello di testo, il carattere, lo stile, la grafica, ecc.
- Passaggio 7:esporta il video
Nota:devi comprendere che il riconoscimento degli altoparlanti Python dà il pieno controllo sull'addestramento del modello. Ma Filmora fornisce un approccio automatizzato. La sua funzionalità AI garantisce un riconoscimento efficiente degli oratori senza le complessità della programmazione.
Parte 4:dove posso utilizzare le app di riconoscimento del relatore?

Senza dubbio, il riconoscimento dei relatori in Python sta trasformando diversi settori. Questa tecnologia fornisce un modo rapido e affidabile per identificare le voci nei video o nei file audio. Sta diventando una parte fondamentale di diversi settori. Di seguito sono elencate le aree in cui queste app sono applicabili.
- Assistenti intelligenti e dispositivi a controllo vocale. App come Siri, Alexa e Google Assistant utilizzano l'identificazione dell'oratore per distinguere le voci. Ciò consente risposte personalizzate, accesso sicuro e comandi vocali personalizzati per diversi utenti.
- Sicurezza e autenticazione vocale. Molte aziende utilizzano l'identificazione del relatore per verificare gli utenti e prevenire le frodi. Elimina la dipendenza dalla password migliorando al tempo stesso la protezione dei dati e la comodità dell'utente.
- Trascrizione e appunti di riunione basati sull'intelligenza artificiale. Il riconoscimento degli oratori aiuta applicazioni come Otter.ai a differenziare gli oratori. Ciò aumenta la precisione della trascrizione, soprattutto quelle con più note vocali.
- Call center e assistenza clienti. I call center utilizzano il riconoscimento degli oratori in Python per migliorare l'autenticazione e il rilevamento dei clienti. I sistemi basati sull’intelligenza artificiale identificano i chiamanti tramite voce, riducendo la necessità di verifica manuale dell’identità. Ciò migliora la sicurezza, l'efficienza e i tempi di risposta nel servizio clienti.
- Sanità e accessibilità. Gli ospedali e le app sanitarie utilizzano l'identificazione del relatore per l'autenticazione sicura del paziente. Gli strumenti di intelligenza artificiale basati sulla voce aiutano le persone con mobilità limitata ad accedere ai dispositivi senza interazione fisica. Il riconoscimento degli altoparlanti Python garantisce un accesso medico sicuro e migliora la cura dei pazienti.
Conclusione
Python è uno dei linguaggi più popolari per l'identificazione del parlante e della voce. Fornisce potenti librerie come SpeechRecognition, PyAudio, Librosa e Pico Voice Eagle SDK.
Questi strumenti consentono un'elevata precisione e un'identificazione dell'oratore in Python in tempo reale . Ciò lo rende l’opzione migliore per sviluppatori, ricercatori di intelligenza artificiale e applicazioni di sicurezza. Filmora offre un'alternativa più semplice per chi non ha competenze di programmazione. Fornisce conversione da parlato a testo, modifica vocale e riconoscimento dell'oratore senza richiedere la codifica Python.
Prova gli strumenti basati sull'intelligenza artificiale di Filmora per l'editing vocale e la trascrizione automatici. Rendono il processo veloce e amichevole.

Filmora
⭐⭐⭐⭐⭐
Il miglior software e app di editing video basati sull'intelligenza artificiale