Convertire la voce in testo non è mai stato così facile, grazie ai modelli di sintesi vocale di Hugging Face. Che tu stia trascrivendo interviste, generando sottotitoli o sviluppando applicazioni basate sull'intelligenza artificiale, Hugging Face fornisce un riconoscimento vocale all'avanguardia basato su modelli avanzati di apprendimento automatico. La parte migliore? È altamente personalizzabile e ti consente di perfezionare i modelli per una migliore precisione e prestazioni in base alle tue esigenze specifiche.
In questa guida ti spiegheremo come configurare e utilizzare l'API Hugging Face di sintesi vocale , esplora le sue opzioni di personalizzazione e discuti casi d'uso pratici. Ma cosa succede se hai bisogno di un’alternativa più semplice? Non preoccuparti:introdurremo anche uno strumento di sintesi vocale facile da usare che consente di svolgere il lavoro senza sforzo. Che tu sia uno sviluppatore, un creatore di contenuti o un professionista, questa guida ti aiuterà a trovare la migliore soluzione di sintesi vocale per il tuo flusso di lavoro, continua a leggere.
In questo articolo
- Come funziona il discorso del viso abbracciato al testo
- Configurazione della sintesi vocale del volto abbracciato al testo
- Un'alternativa più semplice:sintesi vocale automatica con Filmora
- Quale strumento è il migliore
Parte 1:Come funziona il discorso del viso abbracciato al testo
Hugging Face Speech-to-Text è un'ottima funzionalità all'interno della libreria Hugging Face Transformers che ti consente di trasformare le parole pronunciate in testo scritto utilizzando modelli pre-addestrati. Utilizza la tecnologia avanzata di riconoscimento vocale automatico (ASR) per trascrivere il parlato. Con architetture basate su trasformatori come Wav2Vec2, il sistema elabora i dati audio e li converte in testo. E lo fa con grande precisione.
Una delle cose che rende Speech-to-Text in Hugging Face risalta è l'integrazione della pipeline che lo rende estremamente semplice per gli sviluppatori. Con solo poche righe di codice puoi elaborare file audio e ottenere trascrizioni di testo. Inoltre, dispone di modelli preaddestrati per più lingue e scenari vocali, quindi è adattabile a molti casi d'uso.
Il processo di sintesi vocale segue una sequenza passo passo per garantire una trascrizione accurata:
- Input audio:fornisci un file audio da elaborare.
- Estrazione di caratteristiche:il sistema estrae caratteristiche vocali, banchi di filtri log-mel. Questo aiuta ad analizzare i modelli sonori.
- Inferenza del modello:un modello di trasformatore preaddestrato elabora le funzionalità e genera token di testo che rappresentano le parole pronunciate.
- Output di testo:il modello converte questi token in una trascrizione di testo.
I modelli di sintesi vocale di Hugging Face, in particolare SeamlessM4T-v2, migliorano l'efficienza implementando un framework a doppia sequenza-sequenza (seq2seq). È dotato di codificatori vocali e di testo separati, nonché di un vocoder HiFi-GAN, che migliora la qualità della voce generata. Si tratta di uno strumento utile per il riconoscimento vocale e l'automazione, con applicazioni che includono assistenti virtuali, sottotitoli in tempo reale, servizi di trascrizione e ricerca vocale.
Parte 2:impostazione del discorso del volto abbracciato al testo
Di seguito è riportata una guida passo passo su come eseguire la configurazione per utilizzare la sintesi vocale abbracciata al testo:
Passaggio 1:crea un account con il volto che abbraccia

Il primo di cui hai bisogno è un account su Hugging Face. La creazione di un account ti dà accesso a modelli e API preaddestrati. Se non hai già un account;
- Vai al sito web del volto che abbraccia
- Fai clic su Iscriviti
- Inserisci i tuoi dati e crea un account
- Una volta effettuato l'accesso, vai alle Impostazioni del tuo profilo
- Trova i token di accesso e crea un nuovo token (scegli "Scrivi" come livello di autorizzazione)
Questo token ti aiuterà a connetterti a Hugging Face dal tuo codice.
Passaggio 2:installa le librerie richieste
La prossima cosa che devi fare è installare tutte le librerie di cui avrai bisogno. Per fare ciò, apri il terminale o il prompt dei comandi e digita:
pip installa trasformatori set di dati torchaudio librosa file audio
Transformers serve per caricare i modelli Hugging Face, torchaudio aiuta a elaborare i dati audio, mentre librosa e soundfile aiutano a caricare e modificare i file audio.
Passaggio 3:carica il modello
Dopo aver installato tutte le librerie richieste, la prossima cosa che devi fare è caricare il modello di sintesi vocale. Puoi utilizzare Wav2Vec2 poiché è uno dei migliori modelli preaddestrati per il riconoscimento vocale.
dai trasformatori importati Wav2Vec2ForCTC, Wav2Vec2Processor
importa torcia
# Carica il modello e il processore
nome_modello ="facebook/wav2vec2-large-960h"
processore =Wav2Vec2Processor.from_pretrained(nome_modello)
modello =Wav2Vec2ForCTC.from_pretrained(nome_modello)
Passaggio 4:converti l'audio in testo
Devi preparare il file audio in modo che il modello possa capirlo. Per raggiungere questo obiettivo, è necessario caricare l'audio nel software. Quindi, assicurati che sia nel formato corretto in modo che il modello possa elaborarlo in modo appropriato. Lo eseguirai attraverso il modello per trasformare il discorso in testo.
importa libri
#Carica un file audio e convertilo a 16kHz
def carica_audio(percorso_file):
audio, sr =librosa.load(file_path, sr=16000)
restituisce l'audio
file_audio ="esempio.wav"
ingresso_audio =carica_audio(file_audio)
Elabora l'input audio in modo che il modello possa leggerlo
valori_input =processore(ingresso_audio, return_tensors="pt", frequenza_campionamento=16000).valori_input

Nota:per progetti più grandi, Hugging Face offre un endpoint API che ti consente di elaborare il parlato in remoto senza gestire il modello sul tuo dispositivo. Registrati semplicemente per un account Hugging Face, ottieni una chiave API e invia file audio tramite una semplice richiesta API.
Come personalizzare i modelli di sintesi vocale
Se vuoi che il tuo modello di viso abbracciato da voce a testo funzioni meglio, devi perfezionarlo. Il modello base è buono, ma potrebbe non comprendere alcuni accenti, rumori di fondo o parole speciali. Addestrarlo con i tuoi dati lo aiuta ad apprendere e migliorare, rendendolo molto più accurato per le tue esigenze. Ecco come puoi ottimizzare il modello:
- Perfeziona con dati personalizzati:addestra il modello con i tuoi set di dati audio e di trascrizione per migliorare il riconoscimento di accenti specifici o termini di settore.
- Regola le impostazioni di inferenza:modifica parametri come la temperatura e la ricerca del raggio per perfezionare la precisione.
- Aggiungi vocabolario personalizzato:insegna al modello nuove parole e frasi pertinenti al tuo dominio.
La personalizzazione rende il modello più preciso e affidabile per le tue esigenze specifiche. Ma se preferisci una soluzione più semplice, consulta la sezione successiva per una semplice alternativa alla sintesi vocale!
Parte 3:Un'alternativa più semplice:sintesi vocale automatica con Filmora
Hugging Face Speech-to-Text sembra troppo complicato e richiede competenze tecniche come la codifica. Ma esiste un'alternativa più semplice:Wondershare Filmora è un approccio molto più semplice per convertire il parlato in testo. Filmora è un popolare software di editing video dotato di uno strumento di sintesi vocale che trascrive automaticamente l'audio con pochi clic.
- Filmora ti semplifica tutto. Quindi non sono necessarie competenze di programmazione o configurazioni complesse.
- Può trascrivere il parlato video in testo con una precisione fino al 99%. Pertanto, creatori di contenuti, studenti e persino professionisti aziendali possono utilizzarlo per generare testo dall'audio in modo rapido e accurato.
- Supporta oltre 45 lingue e funziona bene con sottotitoli video, note vocali e interviste.
- È dotato della traduzione automatica dei sottotitoli per contenuti multilingue
- Puoi generare didascalie animate personalizzabili per migliorare il coinvolgimento
- Inoltre, la funzione di sintesi vocale integrata di Filmora elabora i dati audio molto velocemente e fa risparmiare tempo all'utente. La sua velocità e la capacità di risparmiare tempo sono ciò che lo rendono l'alternativa migliore.
Parte 4:Come utilizzare Filmora Speech-to-Text
Filmora rende molto semplice convertire il parlato in testo. Non è necessario creare codice o impostare nulla di complicato.
Segui semplicemente queste semplici istruzioni per ottenere la tua trascrizione in pochissimo tempo utilizzando la funzione di sintesi vocale del desktop:
Passaggio 1:importa il tuo audio o video
Apri Filmora e aggiungi il tuo file audio o video. Puoi farlo semplicemente trascinandolo sulla timeline. Questo ti rende le cose più facili. Una volta che il tuo file è a posto, sei pronto per andare avanti.
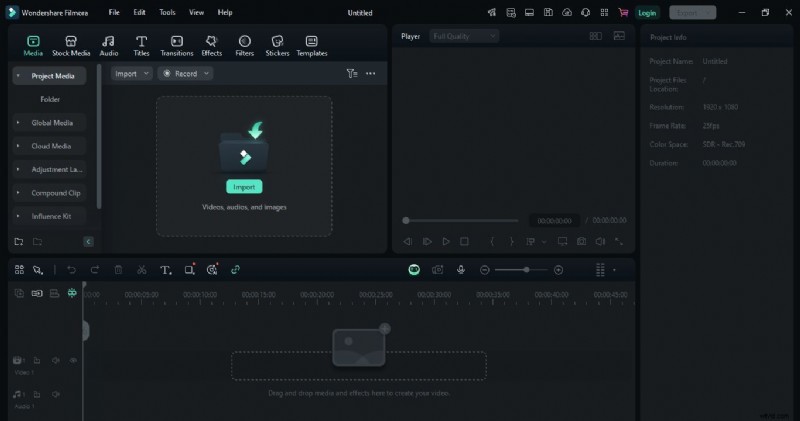
Passaggio 2:seleziona l'opzione di sintesi vocale
Vai su Strumenti nella barra dei menu in alto e fai clic su di esso. Scegli Audio e poi l'opzione Sintesi vocale per analizzare automaticamente il tuo audio. Non è necessario modificare le impostazioni o fare altro poiché gestisce tutto per te.
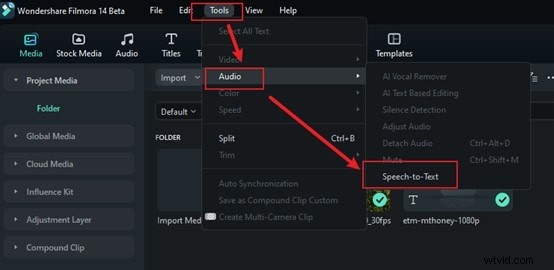
Passaggio 3:scegli la tua lingua
Filmora supporta molte lingue, quindi scegli quella che corrisponde al tuo audio. Questo passaggio è importante perché scegliere la lingua giusta aiuta Filmora a trascrivere il tuo discorso in modo accurato. Se salti questo passaggio, potresti ottenere risultati errati.
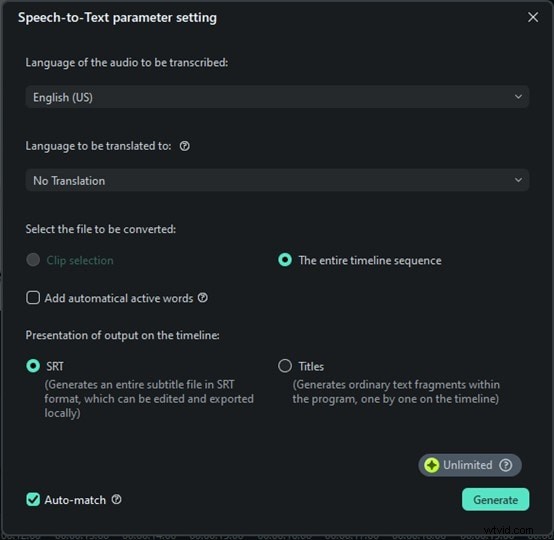
Passaggio 4:avvia la trascrizione e salva
Ora, fai semplicemente clic su Genera e Filmora inizierà a trascrivere il tuo discorso. Questa parte è davvero veloce. In pochi secondi vedrai le parole pronunciate apparire come testo. Nessuna attesa per ore, nessuna configurazione complessa, solo risultati immediati. Fai clic sul file di testo, seleziona Esporta trascrizione del file dei sottotitoli per salvarlo e aggiungerlo come sottotitoli al tuo video.
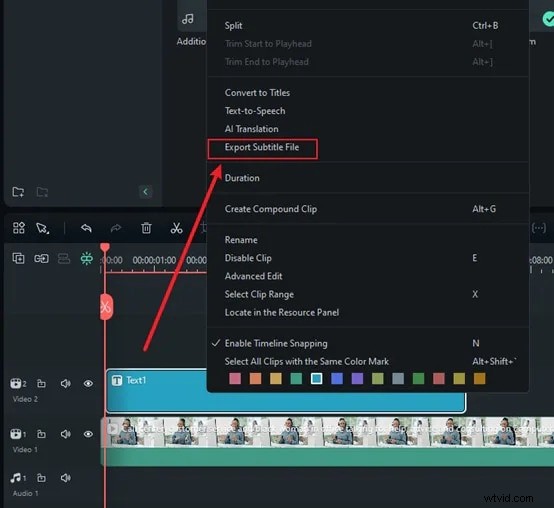
Se desideri convertire il parlato video in sottotitoli di testo, Filmora offre anche una funzione di sottotitoli AI sulla sua app mobile. Ti consente di generare sottotitoli di testo sul tuo dispositivo mobile in meno di un minuto
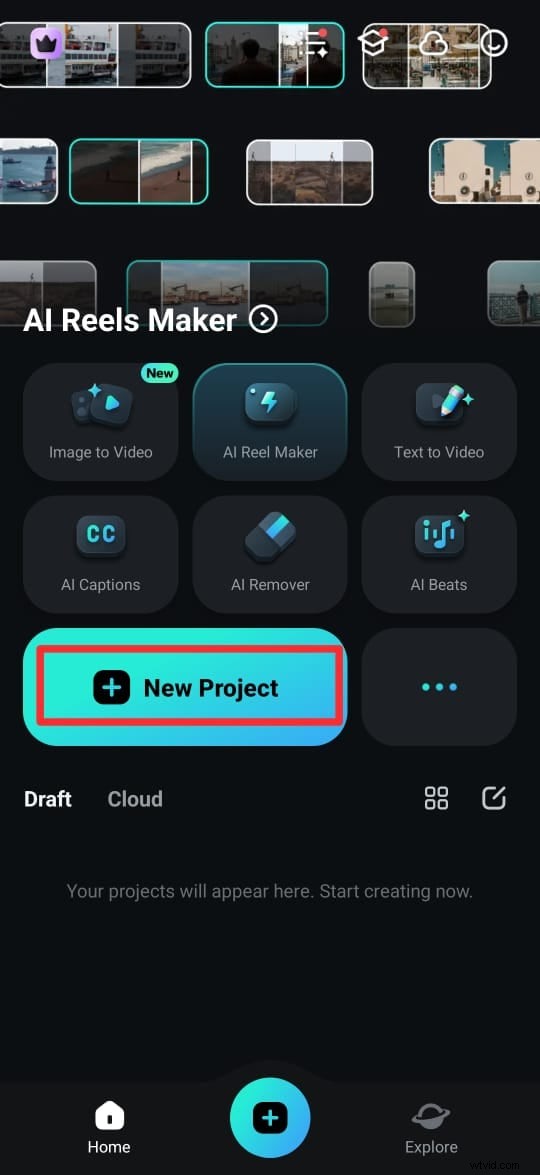
Passaggio 1:Scarica l'app Filmora dal Google Play Store (Android) o dall'App Store (iPhone). Puoi anche ottenerlo dal sito ufficiale. Una volta installata, apri l'app e tocca Nuovo progetto.
Passaggio 2. Scegli un video dalla tua libreria multimediale e tocca Importa per aggiungerlo al tuo spazio di lavoro.

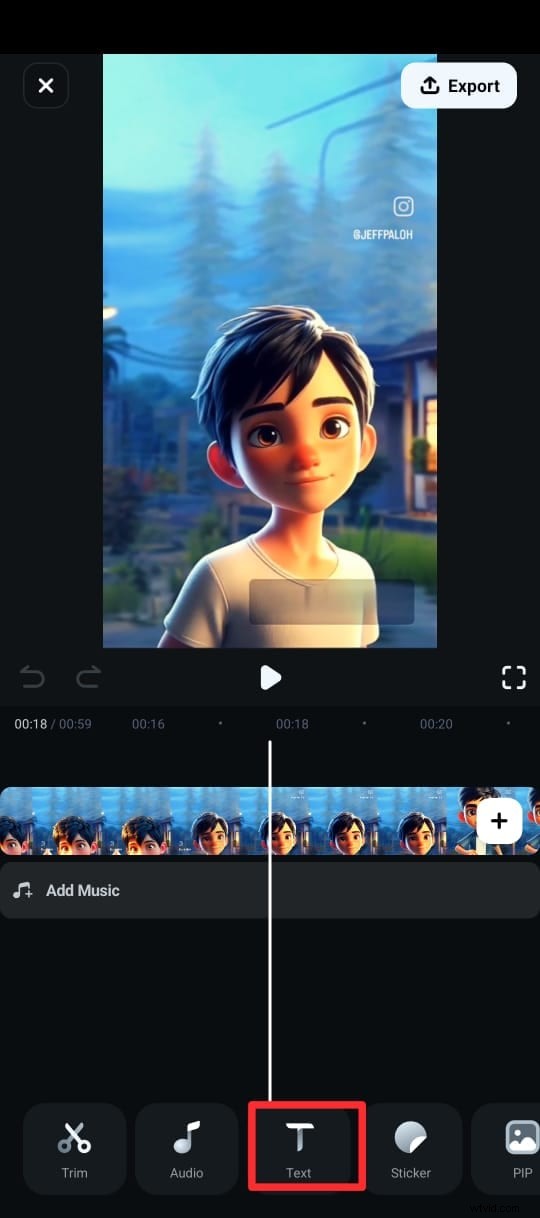
Passaggio 3:nel menu in basso, tocca Testo (contrassegnato da un'icona T) e scegli Sottotitoli AI.
Passaggio 4:nella schermata successiva, seleziona la lingua, attiva il rilevamento dell'altoparlante e tocca Aggiungi didascalie per generare testo dal parlato del video.
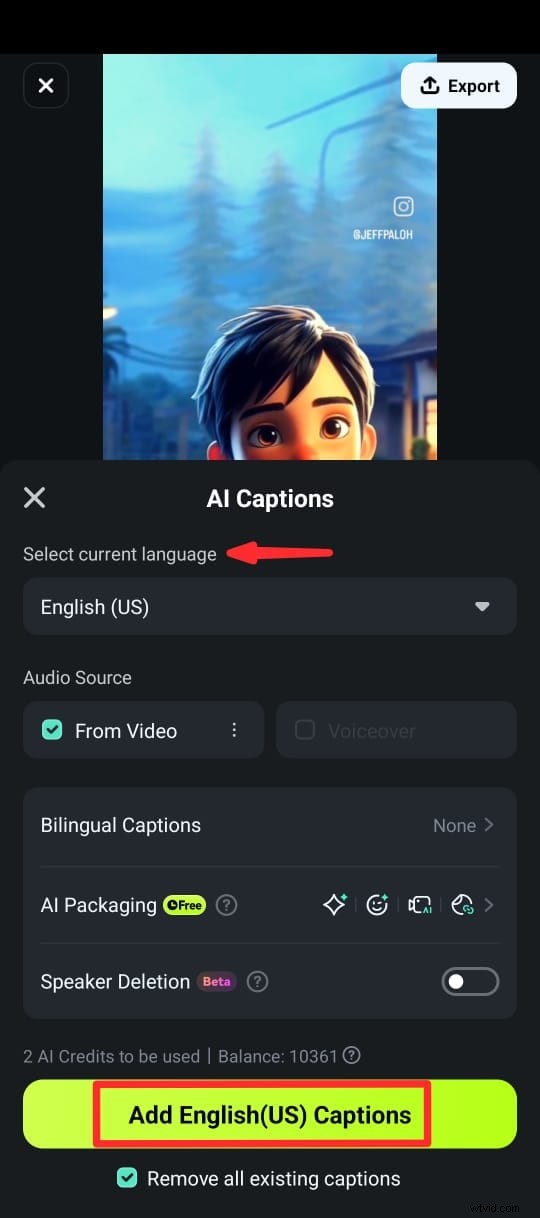
Passaggio 5:una volta generati i sottotitoli, puoi personalizzare il testo utilizzando diversi modelli di testo, emoji e caratteri. Puoi anche modificare il testo nella clip nella timeline selezionando Modifica discorso dalla suite di editing.
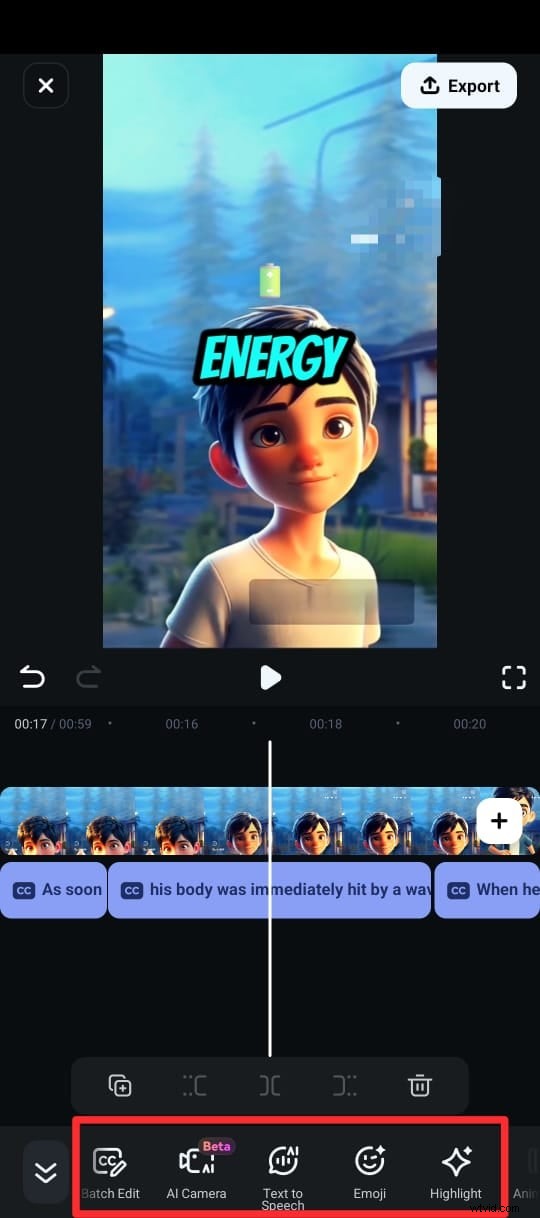
Passaggio 6:esporta il tuo video con i sottotitoli nel formato desiderato.
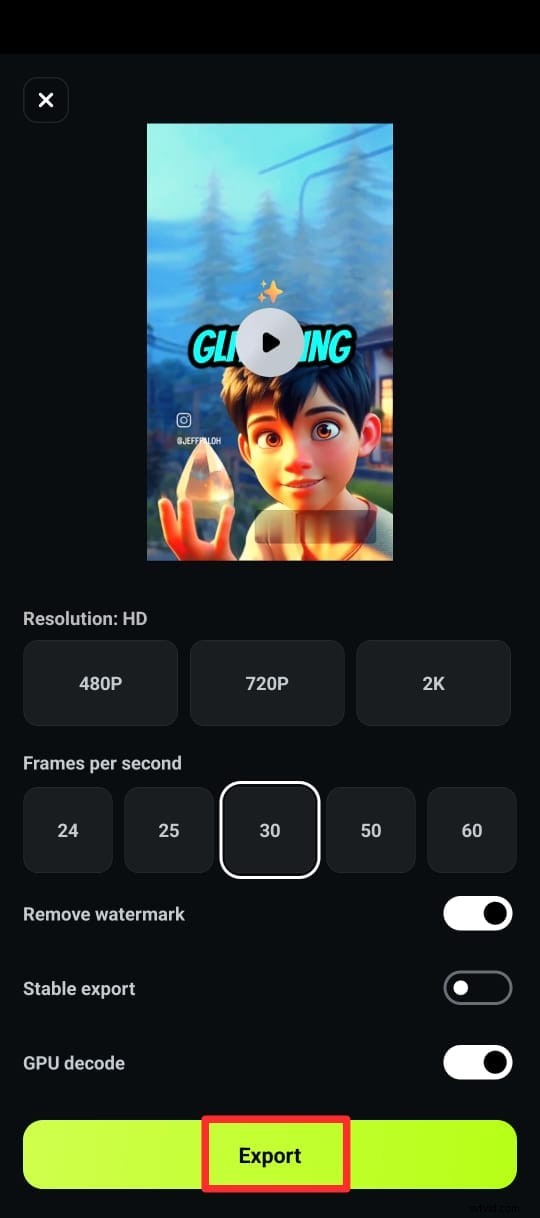
Parte 5. Quale strumento è il migliore?
La scelta tra Hugging Face e Filmora dipende dalle tue esigenze specifiche e dal livello di competenza tecnica. Ciascuno strumento ha uno scopo diverso, quindi esploriamo qual è quello più adatto a te in base ai diversi scenari.
- Se hai bisogno di personalizzazione avanzata e controllo basato sull'intelligenza artificiale, la sintesi vocale di Hugging Face è la scelta migliore. È ideale per sviluppatori, ricercatori e professionisti che desiderano addestrare modelli, ottimizzare i parametri e lavorare con set di dati di grandi dimensioni. Tuttavia, richiede conoscenze di programmazione e tempo per la configurazione, il che lo rende meno adatto ai principianti o a coloro che cercano una soluzione rapida.
- D'altra parte, se desideri uno strumento di trascrizione veloce e accurato senza alcuna configurazione tecnica, Filmora è la strada da percorrere. È progettato per creatori di contenuti, studenti e professionisti che necessitano di una soluzione semplice con un solo clic.
- Utilizza Filmora se aggiungi sottotitoli/didascalie ai video, trascrivi lezioni o converti il parlato in testo per i resoconti.
- Per coloro che lavorano in campi di nicchia che richiedono il riconoscimento vocale specifico del dominio, Hugging Face consente di addestrare il modello sulla terminologia specifica del settore. Ciò garantisce una migliore precisione per il gergo complesso, ma, ancora una volta, richiede impegno e know-how tecnico.
- Nel frattempo, se il tuo obiettivo principale è la trascrizione di contenuti video, Filmora è un'opzione più conveniente, poiché converte rapidamente il parlato in testo, rendendolo ideale per YouTuber, podcaster e creatori di social media.
In sintesi, se ami la programmazione e desideri il pieno controllo e personalizzazione, scegli la sintesi vocale in Huggingface. Ma se desideri uno strumento di trascrizione semplice e istantaneo, Filmora è la scelta perfetta. Scegli quello che meglio si adatta al tuo flusso di lavoro e al tuo livello di competenza.
Conclusione
Convertire la voce in testo non deve essere complicato. Sintesi vocale di Hugging Face è uno strumento potente ma richiede codifica e configurazione, il che è interessante per gli sviluppatori. Tuttavia, se vuoi qualcosa di semplice e veloce, Filmora è la migliore alternativa. Con pochi clic puoi trascrivere l'audio senza sforzo; nessuna codifica, nessuno stress. Perché dedicare ore a configurazioni complesse? Prova oggi stesso la funzionalità di sintesi vocale di Filmora e converti il tuo audio in testo in pochi secondi