Pronti a sbloccare un altro capitolo dell'inarrestabile sviluppo dell'IA? Presentati a tutte le possibilità di sintesi vocale dell'intelligenza artificiale open source e scopri come abbattere le barriere linguistiche con le migliori piattaforme di sintesi vocale open source.
Ottimizza la tua strategia di comunicazione con l'aiuto dell'intelligenza artificiale open source di sintesi vocale e sblocca interazioni multilingue senza interruzioni. Se hai bisogno di un generatore vocale femminile di sintesi vocale come assistente virtuale o desideri imparare una nuova lingua con l'aiuto dell'intelligenza artificiale, sei nel posto giusto.
Resta con noi e scopri le migliori piattaforme TTS open source, compiendo progressi rivoluzionari ed espandendo la portata dei contenuti digitali a un pubblico più ampio.
Le piattaforme di sintesi vocale (TTS) AI open source sono strumenti specializzati per convertire il testo scritto in parole pronunciate con l'aiuto dell'intelligenza artificiale. Queste piattaforme TTS con modelli di apprendimento automatico e algoritmi specializzati sono addestrate per produrre parlato dal suono naturale da testo in varie lingue e voci.
Il fatto che siano open source è semplicemente un vantaggio perché in questo modo sviluppatori e ricercatori possono renderli migliori e più utili.
Le piattaforme di intelligenza artificiale di sintesi vocale open source si stanno espandendo inarrestabilmente con diverse applicazioni in molti campi. Qui abbiamo elencato tutti i potenziali usi a cui potremmo pensare:
Il processo di sintesi vocale AI open source avviene con l'aiuto di algoritmi e modelli avanzati e qui abbiamo cercato di semplificarlo per una migliore comprensione:
I risultati vengono forniti come audio con l'opzione open source per personalizzare la voce e gli accenti.

Wondershare Filmora
Uno strumento di sintesi vocale AI più conveniente e più semplice per i creatori di video di tutti i livelli.Visualizza i dettagli
La funzione TTS di Filmora fornisce oltre 40 tipi di voci, supporta 33 lingue e ti consente di clonare la tua voce nei video. Se non prepari tu i sottotitoli, digita semplicemente le tue richieste e questo strumento si genererà da solo!
Le migliori soluzioni di sintesi vocale AI open source

Le piattaforme di sintesi vocale AI open source offrono varie funzionalità, da voci realistiche e di alta qualità a sistemi flessibili che possono essere adattati a esigenze specifiche. Nei paragrafi successivi, esploreremo le migliori soluzioni open source per aiutarti a trovare lo strumento perfetto.
eSpeak
eSpeak è un'ottima opzione open source per chiunque desideri generare un discorso simile a quello umano. È disponibile in diverse lingue, con versioni per Linux e Windows. Questa piattaforma TTS utilizza un metodo di sintesi delle formanti, consentendo di fornire molte lingue in piccole dimensioni.
Caratteristiche principali:
- Supporta numerose lingue e accenti con regolazione vocale.
- Traduce il testo in codici fonematici e può essere utilizzato come front-end per un altro motore.
- Interfaccia basata su testo per una facile integrazione.
- Le lingue sono fornite in piccole dimensioni.
- Supporto linguistico per varie lingue.
- Facile da integrare in altre applicazioni.
- Le voci sono spesso descritte come robotiche e meno naturali.
- Funzionalità avanzate limitate e personalizzazione vocale.
Discorso irreale
Unreal Speech è un TTS open source progettato per fornire sintesi vocale di alta qualità. Questo software avanzato si distingue per il suo output simile a quello umano e per la straordinaria velocità di conversione del testo, anche per testi estesi.
Caratteristiche principali:
- Voci di alta qualità e dal suono naturale con diversi tipi di contenuti, come narrativa e saggistica.
- In grado di gestire volumi elevati, elaborando migliaia di pagine all'ora.
- Supporta varie lingue e dialetti.
- Efficienza in termini di costi.
- Prestazioni veloci.
- Facile da usare.
- Risultati di alta qualità perfetti per l'uso professionale.
- Flessibile e personalizzabile.
- Configurazione e integrazione potenzialmente complesse.
- Potrebbe richiedere molta potenza di calcolo.
Mozilla TTS

Mozilla TTS è un potente strumento sviluppato da Mozilla e fa parte del loro progetto open source. È perfetto come assistente virtuale e per la creazione di contenuti, progettato per fornire risultati di alta qualità con una forte comunità open source che aiuta il progresso quotidiano di questo software.
Caratteristiche principali:
- Discorso naturale e di alta qualità.
- Offre supporto per più lingue e accenti.
- Consente agli utenti di addestrare e adattare i modelli TTS per creare voci e pronunce personalizzate.
- Facile integrazione e personalizzazione.
- Voci dal suono naturale.
- Forte supporto da parte della comunità.
- Personalizzabile e adattabile a varie applicazioni.
- Aggiornamenti regolari
- L'installazione e la configurazione possono essere complesse per i principianti.
- Ad alta intensità di risorse
Coqui TTS

Coqui TTS è l'evoluzione del progetto TTS di Mozilla e prende il nome dalla rana Coquí, simbolo della cultura portoricana. Perfetto come assistente virtuale o strumento di accessibilità per chi ha difficoltà di lettura, Coquie offre risultati vocali di alta qualità e dal suono naturale.
Questo software di sintesi vocale open source non è più gestito attivamente ma è accessibile su GitHub e HuggingFace. Coqui è ancora disponibile come modello di pre-formazione, in modo che gli sviluppatori possano incorporare facilmente questa tecnologia nelle loro applicazioni.
Caratteristiche principali:
- Supporta più lingue e accenti.
- Fornisce la possibilità di addestrare modelli vocali personalizzati e perfezionare quelli esistenti.
- Consentendo una facile integrazione con diverse applicazioni.
- Uscita di alta qualità.
- Ampie opzioni per la personalizzazione e l'addestramento dei modelli vocali.
- Dispendioso in termini di risorse.
- La configurazione iniziale potrebbe essere complicata.
MaryTTS

MarryTTS è una piattaforma di sintesi vocale multilingue open source completamente sviluppata in Java. Grazie alla sua natura open source, questo software consente la comunicazione e la collaborazione reciproca tra utenti e sviluppatori, il che si traduce in un miglioramento costante. È perfetto per la ricerca e l'uso commerciale.
Caratteristiche principali:
- Supporto multilingue con più lingue e voci.
- Facile integrazione nelle applicazioni Java.
- Design flessibile con ampia personalizzazione.
- Forte supporto da parte della comunità.
- Risultati di alta qualità e dal suono naturale.
- Gratuito e open source.
- La configurazione iniziale e l'integrazione potrebbero essere complesse.
- Supporto limitato per funzionalità avanzate.
Uberduck

Ubedruck è una piattaforma di sintesi vocale open source specializzata in voci AI. Sebbene possa generare un parlato normale, il campo d'azione principale di questo software TTS è la trasformazione del testo in canto o rap.
Caratteristiche principali:
- Vari modelli vocali, incluse opzioni espressive e basate sui personaggi.
- Supporta più lingue e accenti.
- Funzionalità di creazione vocale personalizzata, comprese soluzioni vocali personalizzate.
- Uscita vocale di alta qualità e dal suono naturale.
- Interfaccia intuitiva con facile integrazione.
- Opzioni vocali versatili.
- Opzioni gratuite limitate.
- Set di competenze avanzate necessarie per personalizzazioni più complesse.
- Dipendenza dalla connettività Internet per i servizi basati su cloud.
Sistema di sintesi vocale del festival

Il sistema di sintesi vocale del Festival è una struttura testo-suono sviluppata dal Centro per la ricerca sulla tecnologia vocale dell'Università di Edimburgo. Viene utilizzato principalmente per la ricerca accademica ma è molto utile per applicazioni pratiche.
Festival è un sintetizzatore multilingue con ampia personalizzazione vocale e possibilità di cambiare la lingua predefinita in qualsiasi momento durante la sessione.
Caratteristiche principali:
- Supporta più lingue e modelli vocali.
- Piattaforma open source con ampie opzioni di personalizzazione.
- Include strumenti per lo sviluppo e l'implementazione di sistemi TTS.
- Gratuito e open source, con un background accademico, incoraggia la ricerca e l'innovazione.
- Estremamente personalizzabile ed estensibile per diverse applicazioni.
- Forte supporto accademico e comunitario.
- Richiede competenze tecniche per la configurazione e la personalizzazione.
- Potrebbero mancare alcune funzionalità avanzate per uso commerciale.
- Integrazione complessa per applicazioni moderne basate sul web.
Tacotron 2
Tacotron 2 è una piattaforma di sintesi vocale avanzata sviluppata da Google. È specializzato nella produzione di parlato naturale e di alta qualità dal testo. Grazie ai meccanismi di attenzione e ai modelli sequenza per sequenza, l'output di questo strumento Google è estremamente chiaro ed espressivo.
Caratteristiche principali:
- Risultati di alta qualità con un parlato dal suono naturale.
- Utilizza l'apprendimento da sequenza a sequenza con meccanismi di attenzione.
- Capace di produrre discorsi espressivi e contestualmente appropriati.
- Tecniche avanzate utilizzate per risultati espressivi, dal suono naturale e di alta qualità.
- Combina i modelli Tacotron e WaveNet per prestazioni di alta qualità.
- Tecnicamente impegnativo.
- L'architettura complessa rappresenta una sfida per le implementazioni.
- Dipende da dati di alta qualità per la qualità della voce.
Bonus:la migliore piattaforma di sintesi vocale a sorgente chiusa - Filmora
Potresti non pensare agli editor video quando pensi alle piattaforme di sintesi vocale, ma Wondershare Filmora ha recentemente ampliato la sua offerta con un approccio TTS innovativo. Con l'estrema facilità d'uso e le continue innovazioni di Filmora, la sua funzionalità di sintesi vocale deve risvegliare la curiosità poiché tutte le piattaforme TTS open source possono essere complesse.
La funzione TTS di Filmora è perfetta per i creatori di contenuti che desiderano voci fuori campo veloci e di alta qualità senza attrezzature speciali. Con pochi clic, puoi trasformare il testo in un discorso realistico senza software complessi e con risultati professionali. Questo programma Wondershare semplifica l'intero processo permettendoti di scegliere la voce o clonare la tua.
Con due modalità di generazione intelligente, in Filmora puoi copiare il testo a cui vuoi dare voce o utilizzare la funzione AI Copywriting per generare testo in base all'argomento. Inoltre, puoi scegliere tra 33 lingue con aggiunte e miglioramenti costanti.
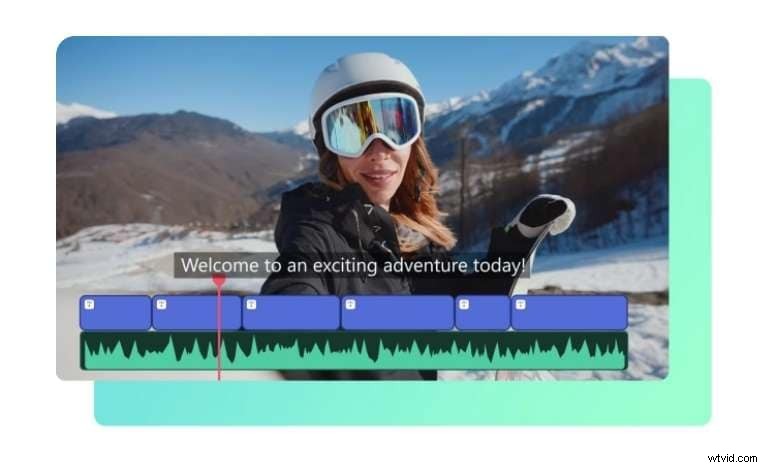
E non sono necessari ritagli e modifiche in modo che il testo possa adattarsi correttamente in linea con il video. Filmora fa tutto questo per te automaticamente. Come puoi vedere, Filmora è progettato per garantire che tutti gli utenti con competenze di base possano creare e ottenere risultati professionali.
Nel complesso, la funzione di sintesi vocale di Filmora è la nuova migliore amica dei tuoi contenuti e ti aiuta a scoprire come Wondershare arricchirà un set già straordinario di strumenti IA.
Conclusione
Esplorando le migliori piattaforme di sintesi vocale AI open source, abbiamo appreso che il concetto di open source è estremamente utile ma complesso. Dai risultati robotici di eSpeak agli output melodiosi di Uberduck, queste diverse piattaforme rappresentano funzionalità rivoluzionarie per la vita di tutti i giorni.
Che tu abbia bisogno di uno strumento da utilizzare come assistente virtuale o desideri uno strumento per dare voce al tuo libro, le possibilità di TTS sono enormi e in costante sviluppo.
Cerchiamo la continua evoluzione di queste piattaforme, ma con la loro complessità speriamo che la semplicità sia un accento per lo sviluppo futuro. Fino ad allora, lo strumento di sintesi vocale Filmora AI è a tua disposizione per ottenere risultati professionali con facilità.