GPT‑Image2 di OpenAI, rilasciato il 21 aprile 2026, è il modello di immagine più recente dell'azienda e il successore di DALL‑E. Introduce un cambio di paradigma:le immagini non sono più generate da un processo di diffusione ma da un sistema autoregressivo che pensa, progetta e verifica prima di disegnare. Il risultato è un modello che offre immagini realistiche, testo multilingue fluente e un livello di ragionamento integrato che lo distingue da ogni altro generatore di immagini AI sul mercato.
Rapporto rapido
- GPT‑Image2 è ora l'unico modello di immagine di OpenAI, in seguito al ritiro di DALL‑E2 e 3 il 12 maggio 2026.
- La sua architettura autoregressiva rispecchia la logica di generazione del testo utilizzata in GPT‑4o, fornendo una pipeline coerente per pixel e parole.
- La precisione del testo è balzata al 99% in inglese e a oltre il 90% in cinese, giapponese, coreano, hindi, bengalese e arabo.
- Il modello può pianificare layout, estrarre dati dal Web e verificare autonomamente i risultati prima di finalizzare l'immagine.
- Le proporzioni vanno da 3:1 a 1:3, con supporto nativo 16:9 e 9:16. L'output standard è 2K; 4K è disponibile nella beta dell'API.
- Questo articolo spiega il cambiamento architetturale, le cinque funzionalità di maggiore impatto, i suoi limiti, un confronto con Midjourney, FLUX e Nano Banana2 e come incorporarlo in un flusso di lavoro più ampio con InVideo.
Che cos'è ChatGPT Images2.0?
GPT‑Image2 rappresenta un output più che nitido; si comporta come un partner creativo. Invece di tradurre le istruzioni direttamente in pixel, il modello interpreta l’intento, pianifica la composizione e perfeziona l’immagine finale. È disponibile all'interno di ChatGPT e tramite l'API OpenAI, posizionato come generatore di risorse di livello produttivo per flussi di lavoro di progettazione reali.
Come GPT‑Image2 può trasformare il tuo flusso di lavoro creativo
1. Testo accurato in un solo passaggio
Con una precisione del testo del 99%, titoli, sottotitoli e CTA vengono visualizzati correttamente al primo tentativo, senza bisogno di ritocchi in Photoshop o modifiche da parte del designer. Un marchio DTC può generare dieci varianti di annunci, ciascuna con un testo unico, e spedire direttamente le risorse finali.

2. Mockup di confezioni ed etichette del prodotto
La copia del marchio su un'etichetta non è più un punto debole. GPT‑Image2 scrive accuratamente i nomi dei prodotti e gli slogan in più lingue (mandarino, hindi, giapponese, coreano e arabo) in modo che i brand globali possano lanciare immagini che corrispondano al loro testo fin dal primo giorno.

3. Risorse sociali in ogni formato
Le proporzioni ora vanno da 3:1 a 1:3, inclusi 16:9 e 9:16 nativi. Un singolo prompt può produrre una miniatura di YouTube, una storia di Instagram, un banner di LinkedIn e diapositive di un carosello senza alcun ritaglio.

Miniatura di YouTube

Copertina di Instagram

Diapositive a carosello
4. Infografiche semplificate
I layout densi rimangono coerenti. Più punti dati, etichette e intestazioni rimangono dove li posizioni, consentendo ai brand B2B di convertire report ricchi di statistiche in infografiche pulite e specifiche del marchio senza dover passare a un designer.

5. Personaggi, ambienti e illustrazioni coerenti
Dai personaggi dei giochi alle mascotte del marchio, GPT‑Image2 può generare personalità uniche, mondi fantastici, città futuristiche e ambientazioni storiche, il tutto mantenendo la coerenza visiva tra le scene.



Scrittori, creatori di fumetti ed editori possono utilizzare GPT‑Image2 per visualizzare ritmi narrativi e sperimentare la narrazione visiva.


6. Mockup di interfaccia utente e concetti
Seguendo attentamente le istruzioni, GPT‑Image2 produce modelli di interfaccia utente puliti partendo da una semplice descrizione della schermata. I team di prodotto possono consegnare l'output agli sviluppatori o alle parti interessate per l'approvazione.
7. Copertine e impaginazioni editoriali
Le copertine delle riviste e i layout dei libri traggono vantaggio dalla rapida esplorazione dei concetti. Le immagini generate dall'intelligenza artificiale possono dare vita alle storie di copertina in modi unici, mentre le illustrazioni editoriali mantengono uno stile visivo coerente su tutte le pagine.



Dove GPT‑Image2 non è ancora all'altezza
- Il riporto della sessione può introdurre rumore; riavviare le sessioni tra i batch per una qualità ottimale.
- La generazione ripetuta di poster può convergere su un unico stile:varia i suggerimenti con direttive di stile esplicite per mantenere la diversità.
- La fisica, l'accuratezza strutturale, i dati tecnici, i volti ravvicinati e il testo su superfici curve o ripide rimangono impegnativi. Tratta i risultati come un solido punto di partenza che richiede ancora una revisione umana.

Le cinque principali funzionalità che distinguono GPT‑Image2
1. Ragionamento integrato
Prima di disegnare un pixel, il modello analizza il prompt, pianifica la composizione, recupera dati esterni e verifica il proprio output, rispecchiando la logica di ragionamento dei modelli di testo di OpenAI.
2. Precisione di rendering del testo del 99%
GPT‑Image1.5 offriva una precisione del 90–95%; GPT‑Image2 dichiara il 99% per gli script latini e CJK, rendendo gli output a passaggio singolo pubblicabili senza ulteriori modifiche.
3. Supporto multilingue
Cinese, giapponese (Kanji e Hiragana), coreano, hindi, bengalese e arabo vengono tutti riprodotti in modo accurato, sbloccando mercati che i modelli precedenti non potevano servire.
4. Alta risoluzione e proporzioni flessibili
L'output standard è 2K (2048px). 4K è in versione API beta. Le proporzioni ora includono da 3:1 a 1:3, 16:9/9:16 nativo e quadrato, eliminando la necessità di ritaglio.
5. Forte rispetto delle istruzioni e controllo della composizione
I comandi spaziali ("tre robot identici di fila"), i prompt di modifica multipla e la manipolazione degli oggetti in base al nome funzionano in modo affidabile, consentendo a composizioni dense, infografiche, fumetti e pagine di riviste di rimanere coerenti.
GPT‑Image2 rispetto a Midjourney, Nano Banana2 e FLUX
| Modello | Ideale per | Limitazione |
|---|---|---|
| GPT‑Immagine2 | Immagini con testo pesante, testo multilingue, lavoro preciso nel layout, seguito delle istruzioni, coerenza di più immagini | La fisica e il testo 3D necessitano ancora di revisione umana; ecosistema più piccolo |
| Metà viaggiov8 | Pura estetica visiva:lavoro editoriale, cinematografico e basato sullo stile | Nessuna API pubblica; testo non latino inaffidabile |
| Nano Banana2 | Flussi di lavoro ad alto volume e sensibili ai costi | Meno precisione su testo denso e layout complessi |
| FLUX (Laboratori della Foresta Nera) | Licenze open-weight, self-hosting e messa a punto | Ecosistema più piccolo, meno distribuzione |
Abbiamo eseguito un unico prompt attraverso tutti e quattro i modelli e confrontato i risultati fianco a fianco.
Prompt: "Create a premium YouTube thumbnail in a modern AI‑tech editorial style. Split the composition into two contrasting halves. On the left side, showcase stunning AI‑generated visuals emerging from a glowing ChatGPT‑inspired interface: cinematic portraits, realistic product photography, vibrant illustrations, and professional marketing creatives. Use bright lighting, vibrant colors, futuristic UI elements, and upward arrows to symbolize benefits and innovation. On the right side, depict the limitations and challenges of AI image generation: distorted hands, inconsistent text rendering, failed generations, quality issues, and warning symbols. Use darker tones, subtle glitch effects, red highlights, and broken image frames to create contrast. In the center, feature a large glowing AI image‑generation panel with an image transforming from rough concept to polished masterpiece. Add dynamic particles, depth, dramatic lighting, and premium tech aesthetics. Large bold headline text: Here’s EVERYTHING YOU NEED TO KNOW ABOUT CHATGPT IMAGES 2.0. Secondary text: BENEFITS vs FALLBACKS Typography should be huge, bold, modern sans‑serif, highly readable at mobile size. Use white text with subtle shadows and cyan accents. Maintain strong visual hierarchy similar to top‑performing AI and technology YouTube thumbnails. Ultra‑sharp, high contrast, professional, viral‑worthy, clean composition, 16:9 aspect ratio."
Accesso a GPT‑Image2
Nella ChatGPT
La generazione dell'immagine di base è gratuita per tutti gli utenti. La selezione di un modello Thinking o Pro sblocca il livello di ragionamento:ricerca sul Web in tempo reale durante la generazione, fino a dieci immagini contemporaneamente e continuità di personaggio/oggetto tra di esse.
In InVideo (con conservazione del contesto)
Pilota automatico
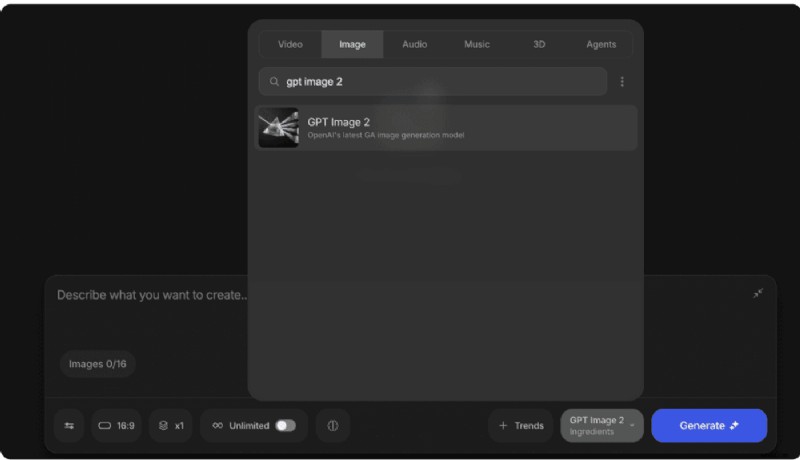
- Passaggio 1: Apri Agenti e modelli, scegli GPT‑Image2.
- Passaggio 2: Scrivi il tuo messaggio, imposta risoluzione e varianti e genera.
Agente Uno
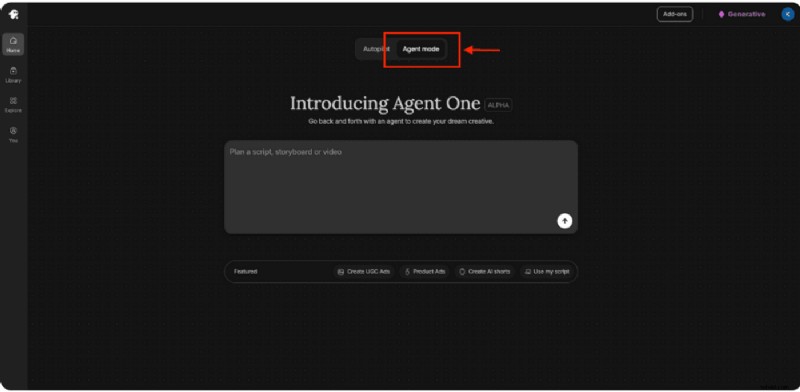
AgentOne richiede solo un passaggio:descrivi ciò di cui hai bisogno in un linguaggio semplice e lascia che sia lui a creare suggerimenti, ideare e produrre variazioni, il tutto preservando il tuo marchio e il contesto della scena.
Domande frequenti
-
Che cos'è ChatGPT Images2.0?
GPT‑Image2 è il modello di generazione di immagini più recente di OpenAI, lanciato il 21 aprile 2026. Sostituisce la vecchia pipeline di immagini GPT e diventa l'unico modello di immagine dopo il ritiro di DALL‑E2 e 3 il 12 maggio 2026.
-
Come utilizzo ChatGPT Images2.0?
Puoi generare immagini direttamente in ChatGPT o tramite InVideo. In InVideo, apri Agenti e modelli, seleziona GPT‑Image2, scrivi un prompt, imposta risoluzione e variazioni e genera. Il contesto del tuo brand viene conservato attraverso le generazioni.
-
Qual è il miglioramento più grande rispetto a GPT‑Image1.5?
La precisione del rendering del testo è passata dal 90-95% circa al 99% dichiarato, consentendo poster, annunci, packaging, menu e modelli di interfaccia utente a passaggio singolo pronti per la produzione.
-
ChatGPT Images2.0 supporta diverse proporzioni?
Sì. Varia da 3:1 (ultra‑wide) a 1:3 (verticale), inclusi 16:9 e 9:16 nativi, più quadrato. L'output standard è 2K; 4K è disponibile nella beta dell'API.
-
GPT‑Image2 può generare testo in altre lingue?
Sì. Rende cinese, giapponese, coreano, hindi, bengalese e arabo, aprendo mercati che i modelli precedenti non potevano servire.
-
Dove ChatGPT Images2.0 non è ancora all'altezza?
Ha difficoltà con la fisica, l'accuratezza strutturale, i dati tecnici, i volti ravvicinati e il testo su superfici curve o con angoli ripidi. La revisione umana è ancora consigliabile per il lavoro di produzione.
-
ChatGPT Images2.0 è migliore di Midjourney?
Dipende dal compito. GPT‑Image2 eccelle in termini di precisione del testo, risorse con un layout pesante, rendering multilingue e rispetto delle istruzioni. La metà del viaggio può portare al puro stile visivo.
-
GPT‑Image2 è un aggiornamento importante?
Sì. È il terzo modello di immagine di OpenAI in tredici mesi, ricostruito da zero con una nuova architettura. DALL‑E2 e3 verranno ritirati, rendendo GPT‑Image2 l'unico modello di immagine che va avanti.
-
In che modo GPT‑Image2 ottiene un testo accurato?
I modelli precedenti apprendevano modelli visivi di testo; GPT‑Image2 è autoregressivo e genera token di testo come linguaggio, garantendo la precisione semantica. Questo cambiamento aumenta la precisione del testo dal 90–95% al 99%.